On-device vs Cloud
A synthesis
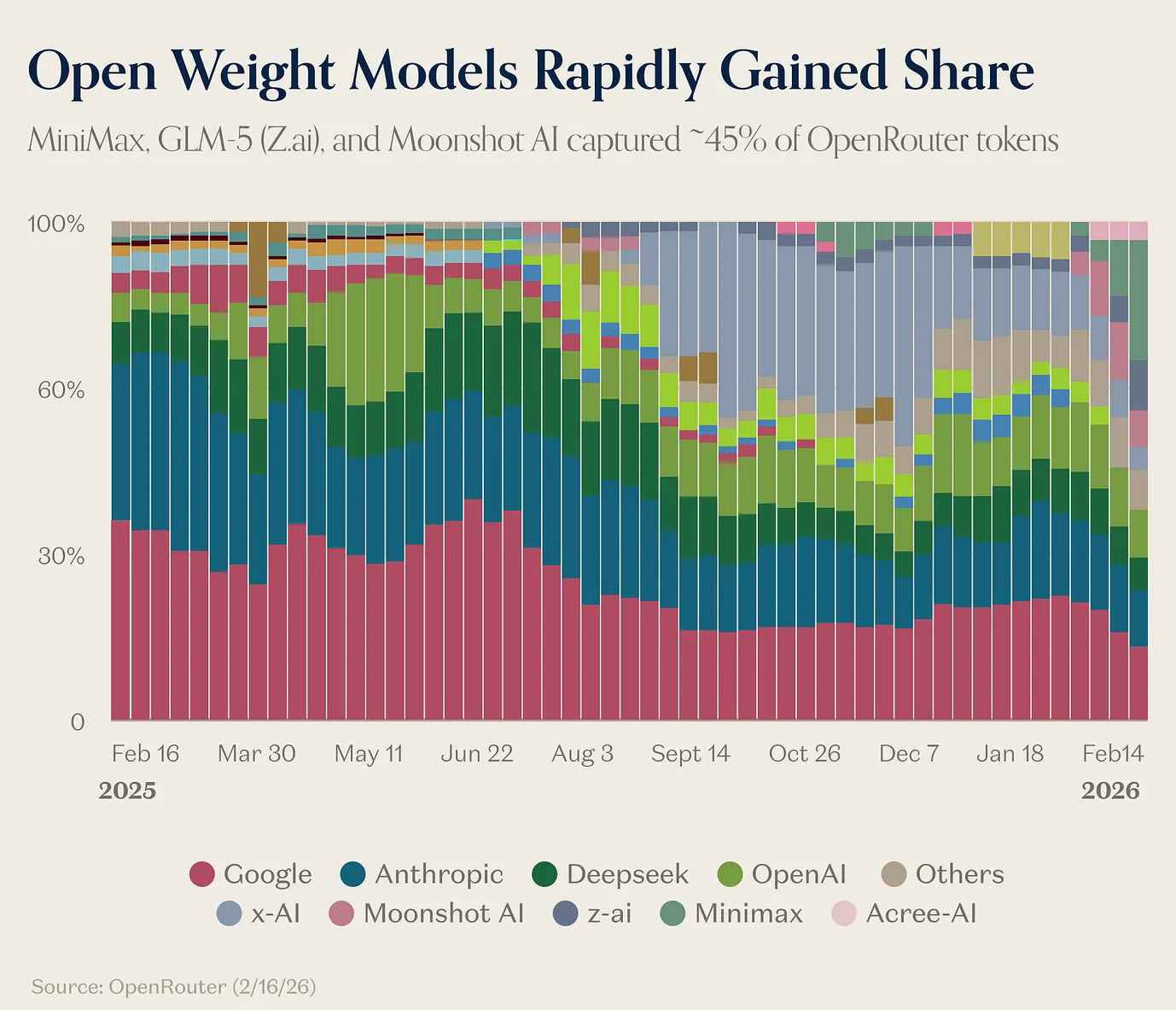
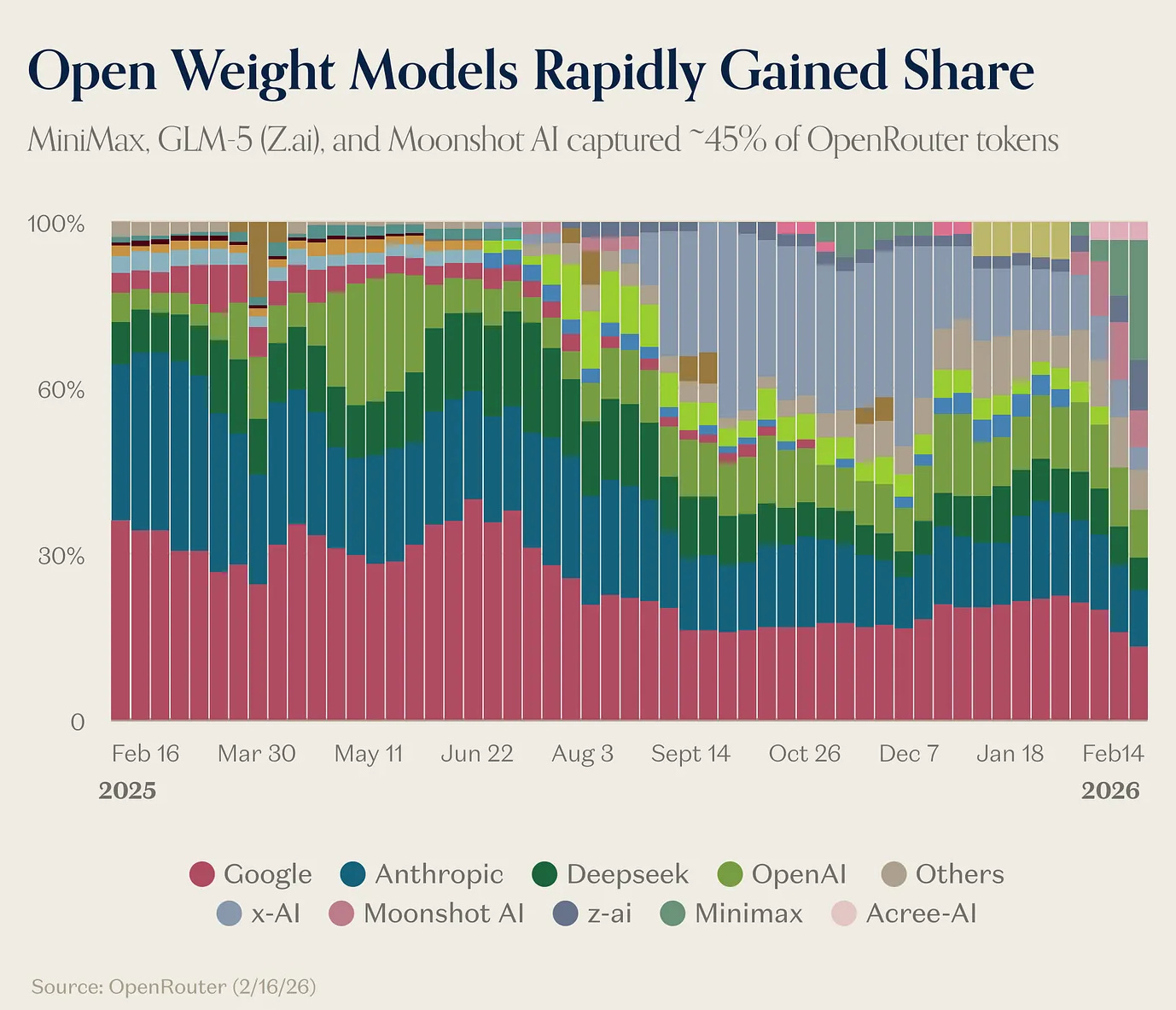
All Praise to the Timeline
X has become the nervous system of this tech cycle. Market-shifting narratives disseminate in hours, leaving many worshiping the timeline and even creating new media formats built entirely around its review (TBPN). Such is the power of the feed, that even investing & writing GOATs like Howard Mark’s are now accidentally citing AI slop essays
Plug into the feed and you’re immediately bombarded with 2 hour workflow tutorials enticing you to hyper optimise your life with OpenClaw. But there’s a cost to abating the AI anxiety. Tinkering with frontier models is an expensive hobby, and most of us don’t have a $100k L&D budget for tokens. Whatever happened to Intelligence Too Cheap To Meter?
This tension sits at the heart of a longer-running debate: Do the frontier god models in the cloud continue to dominate? Or ultimately will AI run where the data already lives? On your phone or laptop
It’s worth decomposing the question, because I’ve found myself conflating two distinct things:
Edge compute is about where the computation happens, specifically on your device, rather than in a data centre. No round-trip to the cloud means it works in bandwidth-constrained environments, and it keeps your data closer to home. The hope is you can run AI inference on-device at lower total cost than calling an API in the cloud
Local access is about what the computation can see and touch, i.e. your files, your calendar, your clipboard, your camera. Crucially, a model running in the cloud can have local access if you grant it the right permissions. A model running on your device has both edge compute and local access by default.
The argument is heating up. Ben Thompson argued for continued cloud dominance via his thin UI thesis. Chamath has been loudly declaring on-prem is back, with more erudite perspectives from Chris Paik & Asad Khaliq. Meanwhile, memory prices are soaring and Raspberry Pi is up almost 100% since it emerged as a lower cost alternative to running OpenClaw on a Mac mini. What better time to consolidate my layman notes around this debate?
One to monitor
On-device is Inevitable?
History shows centralised compute always diffuses to the edge (mainframes to PCs, cloud to mobile) and so for AI inference its a questions of when and for which workloads
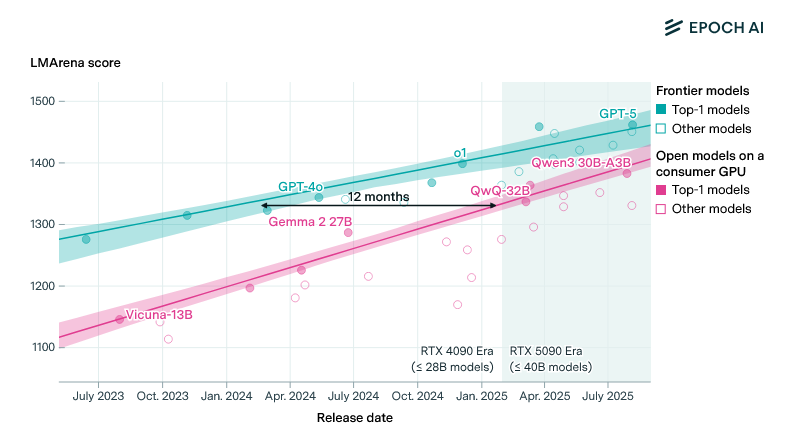
Models are shrinking fast. The success of techniques like distillation have compressed the gap between frontier and open-source models to roughly 12 months. Good open-source models unlock self-hosting, though whether they can also run on-device hinges on how much reasoning survives the compression. Meta’s Llama 3.2 has 1B and 3B parameter versions running on phones. Microsoft’s Phi-3 Mini packs 3.8 billion parameters and outperforms models many times its size on standard benchmarks. Developers can run these via Ollama on laptops today, for real workloads, with no cloud dependency.
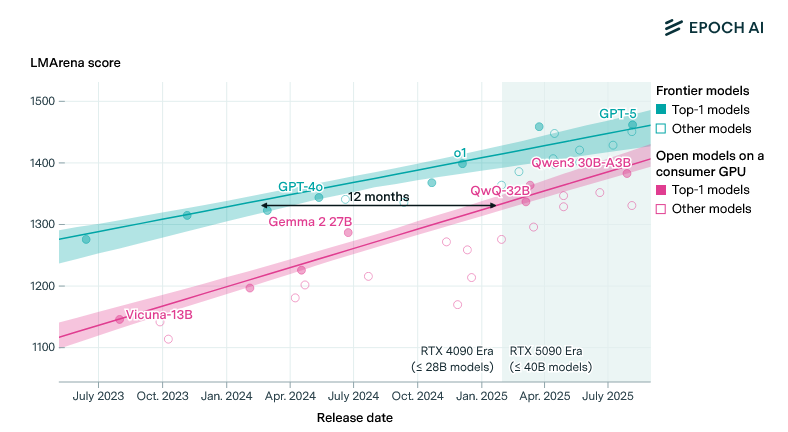
lag between frontier & open source per Epoch AI
Hardware is catching up. Apple’s unified memory architecture is turning the mac into a credible inference machine and MLX, their open toolkit for running and optimising models on-device, removes much of the engineering friction. In this context, Apple’s low capex play makes more sense. Let the cloud wars play out, then position as the trusted personal intelligence orchestrator, sitting between the user and every model. Not so dumb over in Cupertino, unless of course Jony Ive help’s OpenAI pull a hardware miracle out of the hat. One constraint Apple's patience doesn't solve is power. A model doing serious on-device inference hits the CPU and GPU hard and continuously. Long live the portable charger
Upgrade my mac or succumb to the underclass? Economic Incentives. Cloud inference is structurally destroying SaaS margins, with Bessemer putting ‘AI Supernova’ GM’s at just 25%. The logical response is to push commodity workloads to the edge where inference cost approaches zero.There’s also a political dimension: anti-data centre NIMBYs are now a thing. Distributed inference on existing hardware sidesteps the build-out problem entirely, even if the power question doesn’t fully disappear. That’s the pitch right, Elon?
 Elon Musk@elonmuskI am increasingly confident that this idea could work
Elon Musk@elonmuskI am increasingly confident that this idea could work Nic Cruz Patane @niccruzpataneElon Musk came up with a pretty incredible idea during the Q3 Earnings Call, that no one is really talking about. His words: “Actually, one of the things I thought, if we've got all these cars that maybe are bored, while they're sort of, if they are bored, we could actually8:06 AM · Oct 29, 2025 · 37.3M Views5.6K Replies · 9.03K Reposts · 112K Likes
Nic Cruz Patane @niccruzpataneElon Musk came up with a pretty incredible idea during the Q3 Earnings Call, that no one is really talking about. His words: “Actually, one of the things I thought, if we've got all these cars that maybe are bored, while they're sort of, if they are bored, we could actually8:06 AM · Oct 29, 2025 · 37.3M Views5.6K Replies · 9.03K Reposts · 112K LikesSome industries have no choice. Regulated industries cannot send data to the cloud for security reasons and physical AI cannot tolerate cloud latency. Sovereignty and geopolitics concerns are accelerating, with Governments increasingly mandating data localisation and the EU committing to 3x sovereign cloud investment by 2027. For these segments, edge compute is architecturally mandatory.
The labs’ incentives may actually align. As the large labs push further into the application layer, having commodity inference migrate on-device may suit them fine. They keep the agentic and frontier workloads, offload the low-margin commodity calls, and having aggregated the majority of cloud AI demand, hold incredibly powerful negotiating positions against their own infrastructure costs in an overbuild scenario
Related Start-ups: Ditto, Malted, DoubleWord, Edge Impulse, Multiverse Computing, Mirai, Exo labs, Ollama


The Case for the Cloud
The on-device thesis requires a few things to be simultaneously true: (i) models small & fast enough to run locally, (ii) context windows efficient enough for complex tasks, and (iii) enough local memory to handle them. Each is improving, but are fighting rapidly moving goalposts and constrained supply chains
Frontier capability requires scale that devices cannot match. While inference costs per token keep falling, token consumption per task is exploding as agents dramatically increase task length. An agent holding context across a 30-step workflow, making multiple tool calls, and reasoning about results at each step is far more demanding than a simple inference call. That demands data-centre-scale infrastructure, and will for the foreseeable future. Moreover, as debated on r/LocalLLaMA large open source models running locally on consumer hardware run into token per second constraints which may leave them unusable for enterprises
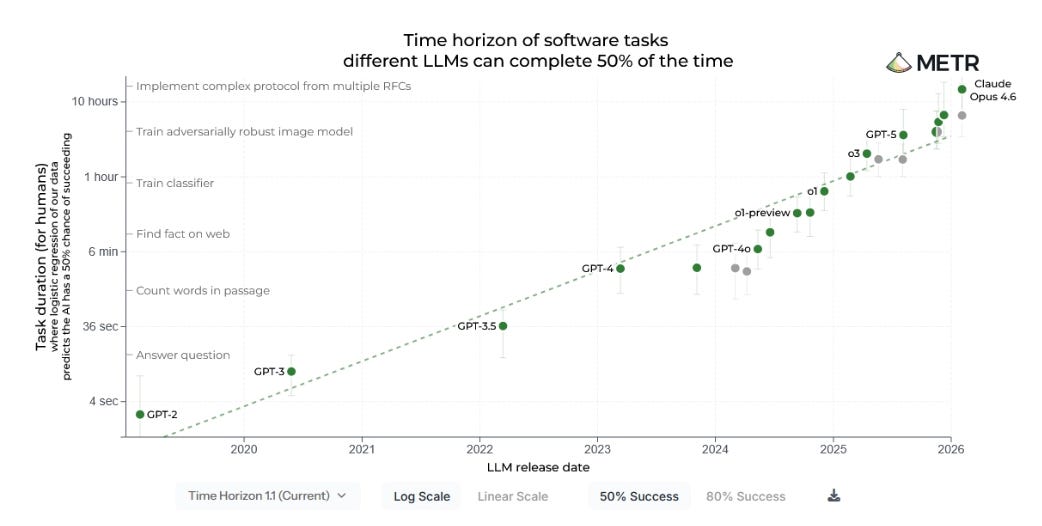
Under appreciated chart
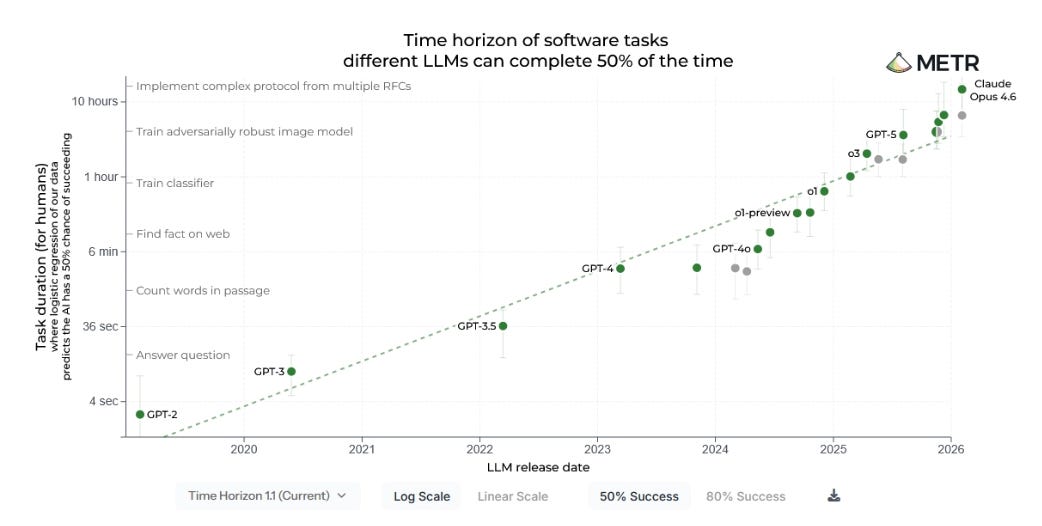
The dominant AI interaction paradigm isn’t device dependent. As Stratechery argued, chat and agentic interfaces require near-zero local compute. In previous software waves, the device mattered because it handled rendering, state management, and UI logic. In AI the quality of your experience is determined almost entirely by the intelligence summoned from a data centre, making the device progressively less relevant to the outcome.
Memory getting expensive. The global memory shortage is making edge hardware more expensive, e.g. an 8GB Raspberry Pi is now around 50% more expensive. If AI computation needs to be on-premises for privacy reasons, there isn’t enough RAM to go around at current production trajectories. Which means much of what Chamath calls “on-prem” will actually run in private cloud enclaves (think AWS Nitro) rather than literal on-device inference. Fumble that I didn’t buy more HBM stocks when mentioning SLM last Sept
Ironically my L/S friend covering memory said not to buy. Fortunately he has a trust fund Centralised compute has a structural cost advantage. Spreading massive capex across millions of concurrent users gives cloud providers utilisation leverage that fragmented edge deployments cannot match. Running your own GPU clusters is brutally expensive: H100s, power, cooling, networking, physical security, cybersecurity, MLOps talent, maintenance contracts. Most enterprises do not want to open this can of worms.
Model velocity creates a deployment trap. Frontier models are improving on a cadence of months. Deploy on-prem today, and you’re running something outdated in six months. Meanwhile, enterprises spending the next 2-3 years building workflows natively on cloud infrastructure are building path dependency that’s very hard to unwind. Repatriation is costly, and the window to make that choice is closing.
The privacy problem is largely already solved in the cloud. The data leakage concern that drives on-device arguments is real, but cloud providers have largely addressed it via VPC isolation, PrivateLink, dedicated infrastructure, encryption at rest and in transit, contractual guarantees against training on customer data.Leakage is mostly an employee behaviour problem, not an infrastructure problem. The EU AI Act and new US state privacy laws are shaping compliance requirements, but they’re driving enterprises toward sovereign cloud (in-country infrastructure) not literal on-device compute.
Who is Right?
Probably boringly nuanced. Heavy agentic workloads go to secure cloud, real-time and sensitive tasks go to edge and regulated industries must adopt sovereign cloud? Intelligent model routing like Sierra’s constellation of models and perhaps Callosum on the infra side are what makes such nuance possible. Small local models handle the majority of workloads and god models in the cloud handle the rest. Enterprises don’t have to make a single binary choice and token usage explodes so fast everybody can ‘win’
The interesting wild card is what happens to AWS, GCP, and Azure as everything consolidates around a few AI vendors? Presumably OpenAI, Anthropic, and xAI decide to vertically integrate cloud ownership the way Meta has and the incumbent cloud majors face a looming disintermediation …
Anyway, i’m interested in speaking with people who have strong opinions on either side of the debate. Better still if you’re building towards an opinionated future where intelligence is actually too cheap to meter. When capabilities that used to be scarce become abundant what new business models are now possible? I’ve got thoughts on jamie@triplepoint.vc